The introduction of the ContentSearch API is a very powerful part of Sitecore 7. It replaced the capable, but considerably more complex Advance Database Crawler created by Alex Shyba. And so began the era of big data in Sitecore.
Being able to debug ContentSearch is a big part of learning how it works and using it successfully. So I'd like to focus on Lucene-powered ContentSearch and how I use Luke to debug it.
Overview:
- Introducing Luke & Luke.NET
- Loading A Lucene Index In Luke
- Overview Of The Lucene Index
- See All The Fields Indexed By Lucene
- Using Luke To Test Lucene Queries
- Using Luke To Test ContentSearch LINQ Expressions
- Confusion Around StorageType
- Choose Your Lucene Analyzer
- Conclusion
Introducing Luke & Luke.NET
Luke is a diagnostic tool for Lucene indexes. This tool is invaluable if we. Originally a Java-based tool, it's been ported to .NET as well.
I've used both versions. To run the Java version, make sure you have Java installed. Double-click the lukeall-4.0.0-ALPHA.jar. The .NET version has an exe.
Loading A Lucene Index In Luke
Seek out your indexes folder at {YourSitecore}\data\indexes folder in SitecoreInside of this folder, each Lucene index has it's own named folder. And since Lucene index consists of a series of files, the folder is what we load. In this case d:\sitecore\data\indexes\efacts_master
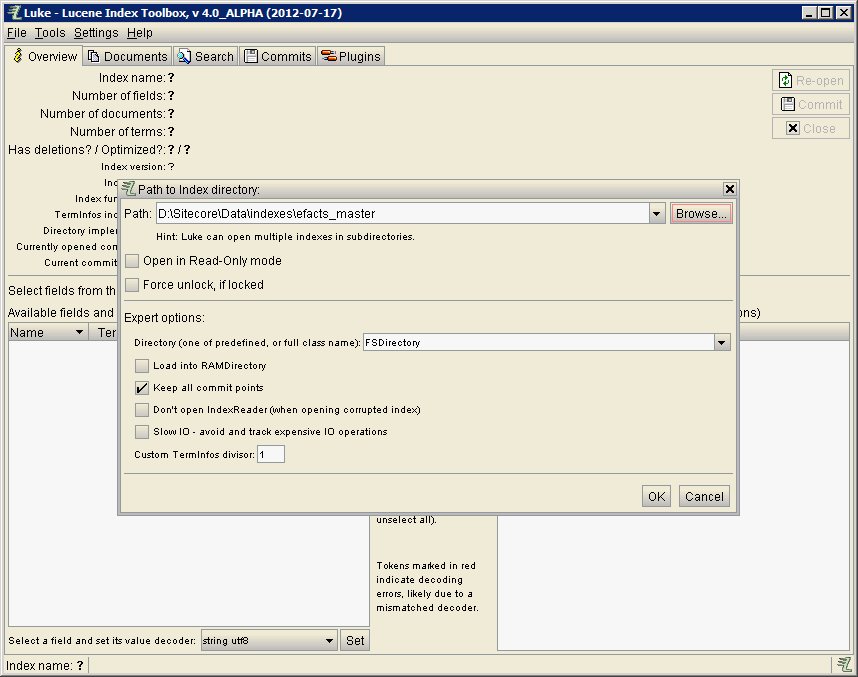
Overview Of The Lucene Index
Deep Breath. Try not to be overwhelmed.

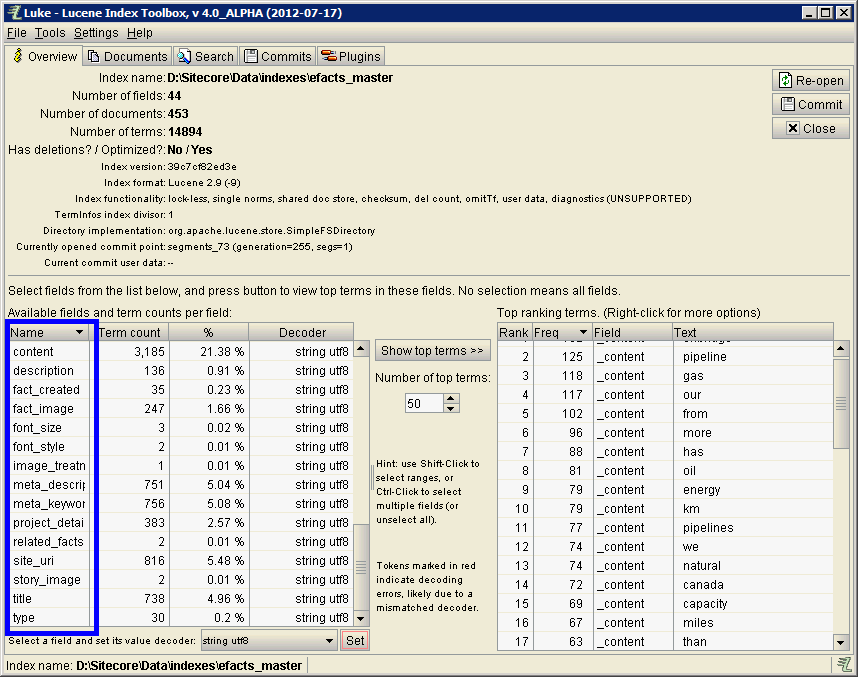
On the left, it's showing all the fields that exist in the index.
All searchable text content is stored in _content the content field. In the above screen-cap, we've highlight _content and clicked Set. Now under Top ranking terms on the right we see the terms stored most frequently in _content. Note "pipeline" is found 125 times, "gas" is 118, et cetera.
An interesting looking at the words we used.
See All The Fields Indexed By Lucene
As mentioned, all indexed fields appear on the left. If you add a new mapped field or computedField, finding it in this list is a good indicator that it's been successfully configured.
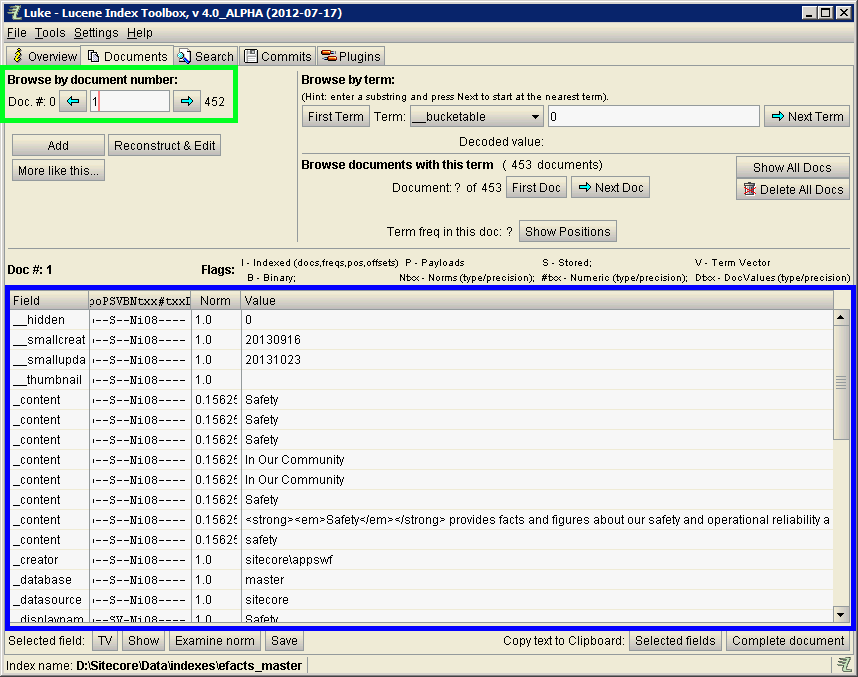
Detailed View Of A Sitecore Item In Lucene
Switch over to the Documents tab. In this view, you can see all fields and values stored on a document (BLUE). You can traverse every document (document = a record in lucene) in the index, one at a time (GREEN).
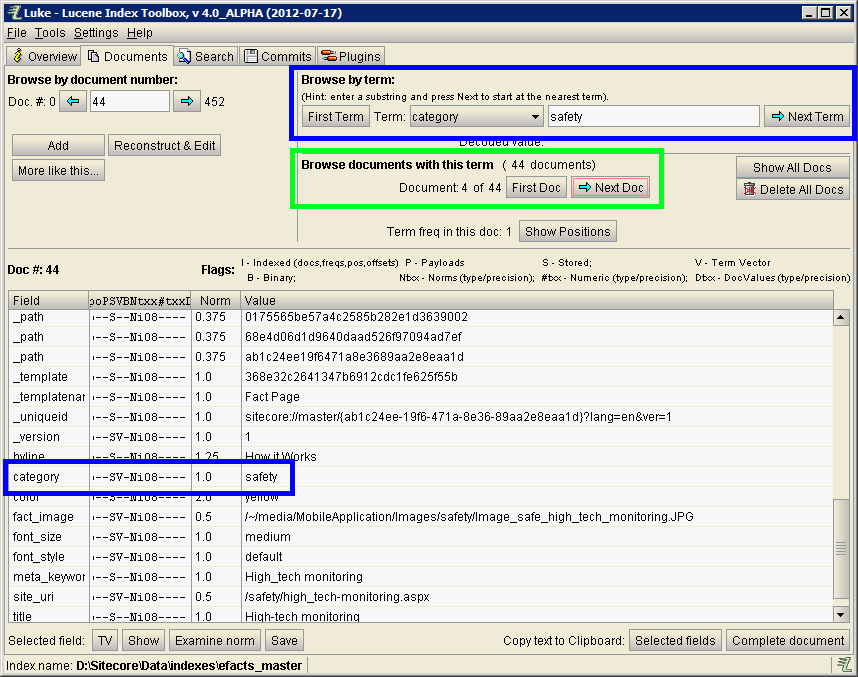
Filter the documents by field value to return a smaller set. In this case, I'm looking for all documents with category set to safety.
Using Luke To Test Lucene Queries
Luke also you test queries and see the value of fields returned in the document. Let's load the search tab and look at the screens.
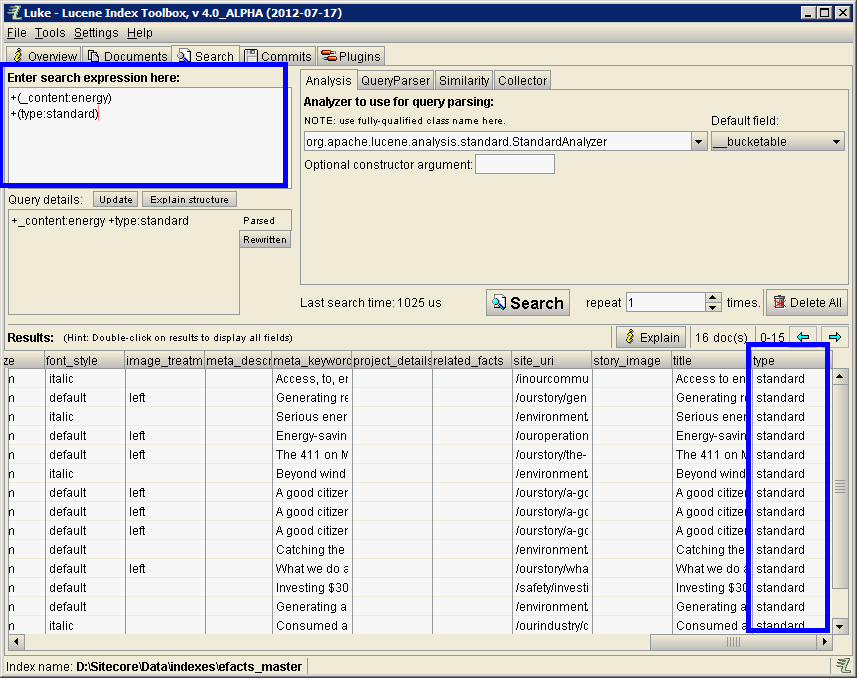
Note the search I entered:
+(_content:energy) +(type:standard)
Breaking it down: _content:energy means I searching the _content field for term energy. Likewise, we're searching the type field for standard.
_content contains tokenized (more on that later) text field content from the item. Where type is a ComputedField that I've added.
The + before each makes them required matches, basically an AND.
From the ContentSearch API an equivalent LINQ expression would be:
context.GetQueryable().Where(i => i["_content"] == "energy" && i["type"] == "standard");
Using Luke To Test ContentSearch LINQ Expressions
There is a log specifically for ContentSearch located at {SitecoreRoot}\Data\logs\Search.log.xxxxxx.txt
When logging is enabled every ContentSearch API call is logged to that file.
Making sure the verbosity of your logging is set to DEBUG, you should be able to do a find for ExecuteQueryAgainstLucene within your log file and locate the last Lucene-equivalent of your last ContentSearch query.
9212 12:22:58 INFO ExecuteQueryAgainstLucene : +(+_content:canada +category_tags:02c8cdd7cbe3408a9f8b026b3b2831ce) +_availableinmediasearch:1
I can copy and paste the query portion of that into Luke and see the results it returns.

Note the relevancy of the results calculated under score and the 119 docs returned.
Confusion Around StorageType
In the ContentSearch config, let's look at a <field /> under fieldMap > fieldNames > field
<field fieldName="title" storageType="NO" indexType="TOKENIZED" …. />
If storageType is set to NO, the field on the document will always appear empty in Luke. The field has been indexed, and is searchable, it's just not stored on the document to be returned as a result.
Here we're searching title:energy which returns results, yet notice the title field on each document is empty.
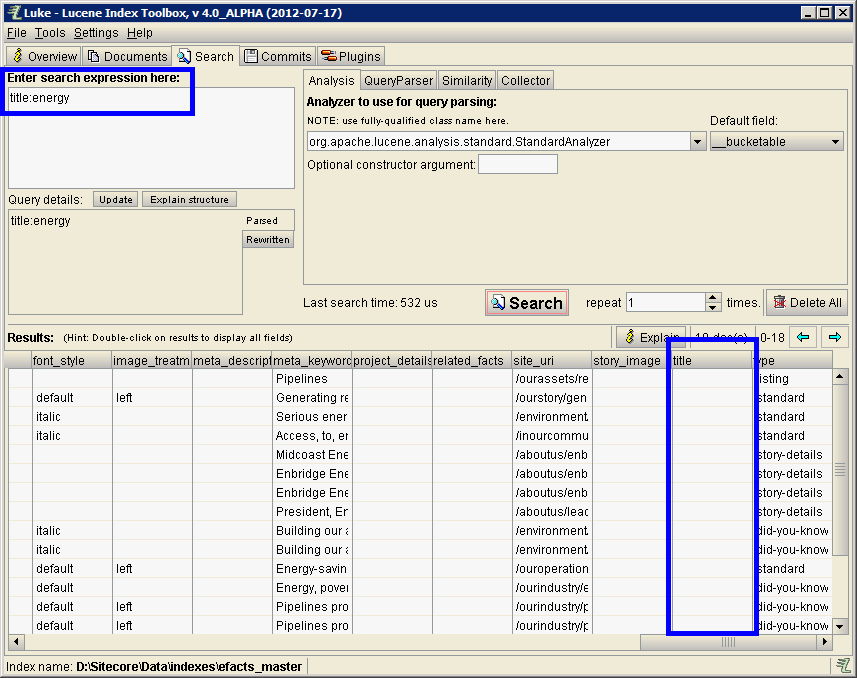
If you don't see the value populated in Luke, the value won't be accessible via ContentSearch.
Tokenized vs Untokenized Fields
If a field is tokenized, it's been broken up word by word, each word stored individually for the purpose of search.
<field fieldName="title" storageType="NO" indexType="TOKENIZED" …. />
If a field with the value of "Energy Is Good" was tokenized, its document would be returned when searching title:Energy or title:Good.
<field fieldName="title" storageType="NO" indexType="UNTOKENIZED" …. />
If it was same field was set to untokenized, its document would only match title:Energy Is Good.
Choose Your Lucene Analyzer
Lucene uses Analyzers to parse and retrieve content. For a simple example, Chinese would require a different Analyzer than English. So before we search, make sure we're executing our queries in Luke with the same analyzer that your Sitecore ContentSearch is using.
In your ContentSearch config, you'll have an analyzer node, that likely points the standard Lucene analyzer, Lucene.Net.Analysis.Standard.StandardAnalyzer
<---
Our index-specific config file
-->
<analyzer ref="contentSearch/indexConfigurations/defaultLuceneIndexConfiguration/analyzer" />
<---
\App_Config\Include\Sitecore.ContentSearch.Lucene.DefaultIndexConfiguration.config
line 104, may not be the same in your version
-->
<analyzer type="Sitecore.ContentSearch.LuceneProvider.Analyzers.PerExecutionContextAnalyzer, Sitecore.ContentSearch.LuceneProvider">
<param desc="defaultAnalyzer" type="Sitecore.ContentSearch.LuceneProvider.Analyzers.DefaultPerFieldAnalyzer, Sitecore.ContentSearch.LuceneProvider">
<param desc="defaultAnalyzer" type="Lucene.Net.Analysis.Standard.StandardAnalyzer, Lucene.Net">
If you're using the Java version of Luke, you'll have to use the equivalent Analyzer.
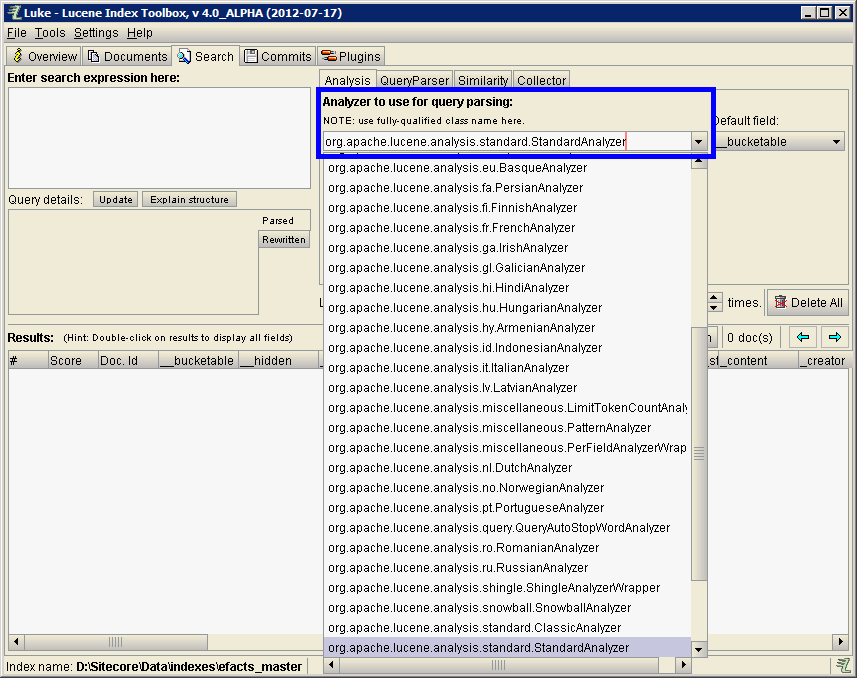
Here's the equivalent screen in Luke.NET.
Conclusion
Lucene is technology onto itself. And to truly understand ContentSearch, you'll need to understand the technology powering it, under the hood. I've found Luke and Luke.NET to be comfortable tools to do just that.
I've been working with Lucene in-depth via the Advanced Database Crawler and now ContentSearch for a number of years now. If you have any questions please find me on twitter @dancruickshank or leave a note in the comments.
This article was authored using Markdown for Sitecore.

